What even is AlphaD3M
Heard about AlphaD3M? Want to know what it is?
You’re in luck!
Overview Link to heading
What is AlphaD3M? It’s an AutoML system. It was first shown at the ICML 2018 AutoML Workshop.
For a given dataset, and a given task, AlphaD3M builds a machine learning pipeline.
Confused? Here’s an example of how this could work.
Dataset: Iris
Task: Multiclass classification of the species column
Metric: Log loss
Pipeline:
- Create new column: | e.g. super_sepal = sepal_width * sepal_length
- Drop column | e.g. petal_width
- Standardise column | e.g. petal_length
- Standardise column | e.g. sepal_width
- Train | e.g. logistic regression classifier
AlphaD3M will automatically change the pipeline around, trying to optimise the log loss of the multiclass classification. Eventually it’ll settle on a solution.
The pipeline built is unique to a dataset and a task. Two pipelines for different tasks might have common elements, but probably won’t be the same.
More details, please Link to heading
At a high level, AlphaD3M is made up of two parts:
- A LSTM recurrent neural network
- A Monte Carlo Tree Search (MCTS)
The output of the LSTM is fed in as the input of the MCTS. Then the output of the MCTS is fed in as the input of the MCtS. It’s a cycle, and it continues until convergence.
This is something called expert iteration.
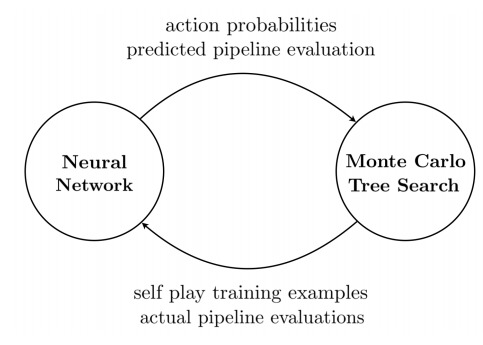
AlphaD3M takes inspiration from reinforcement learning. As such, it frames the problem of AutoML in terms of states and actions.
There are three actions AlphaD3M can take. These are deleting, adding, or replacing a pipeline component.
The output of the LSTM is a vector of probabilities for the agent to take each of these three actions, for every component in the current pipeline.
These are fed into the MCTS, which searches for a better pipeline using these output probabilities. In turn, the MCTS gives the LSTM the improved pipeline it’s found.
The LSTM uses this improved pipeline to update its probabilities. And the cycle continues.
Expert iteration Link to heading
Expert iteration is an idea originating from dual process theory. It makes up a key part of AlphaD3M.
Expert iteration looks like it originated from this paper. It’s an excellent read.
But what is expert iteration?
Traditional reinforcement learning algorithms, like DQN and Policy Gradients, start from scratch each time. There’s all this domain knowledge we know that they miss out on. That’s a problem.
We could use human knowledge to start the algorithm off (like AlphaGo does). But this could bias it towards a human-style way of solving the problem. This isn’t ideal either.
Expert iteration avoids both these traps.
The idea is that you have two parts to the model: an apprentice and an expert.
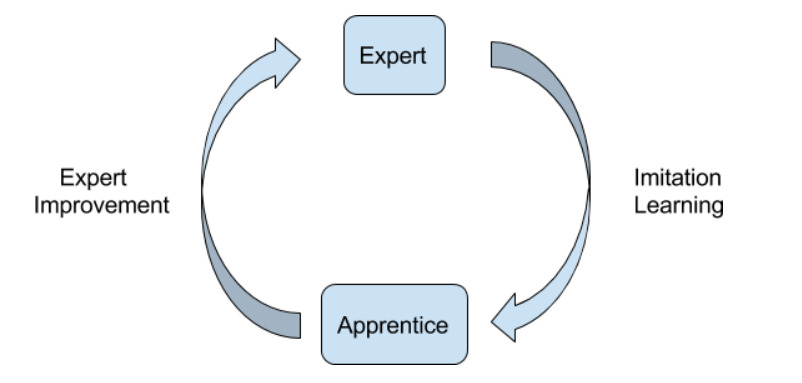
The apprentice is our human intuition; our System 1 network. The master is our structured, logical thought; our System 2 network. Both are useful to solve the problem.
The apprentice first tells the expert to consider some particular moves. The expert thinks it over, makes a move. The apprentice updates itself with the knowledge of the expert’s move. It tries to internalise the expert’s move.
The expert thinks slowly and deeply about possible moves. But there are too many paths and not enough time to consider each one in depth. So it takes hints from the apprentice: look here, and here, but not here. This helps the expert find the best move. The apprentice notes the move. It’ll use it to make better guesses for next time.
AlphaD3M uses a LSTM recurrent neural network as the apprentice and a MCTS for the expert. Both are common choices.
A simple lookup table could have been used for the apprentice, but then it could only guess for states it has seen before. The neural network can generalise to unseen states.
So it goes.
Summary Link to heading
AlphaD3M uses AlphaZero as its inspiration. It treats pipeline building as a single player game, like how AlphaZero solves a two-player game. Both papers use a neural network in combination with MCTS.
As for training data, the majority of the datasets AlphaD3M is tested on are from OpenML. The paper was ambiguous on if the pipelines were also built using OpenML.
The main improvement of AlphaD3M seems to be the speed improvement over other AutoML systems, since performance is around the same level.
AlphaD3M is built in PyTorch, but I can’t find any source code online. Leave a comment if you find it. I’d appreciate it!