Let's build a DQN: neural network architectures
After building the basic DQN, I started trying some different neural network architectures. I found vastly different results between them.
Spoiler: more complex doesn’t equal better. Almost the opposite.
Here are some results for the rewards obtained in each episode. I trained these models on cartpole-v1. Each was trained for 1000 episodes.
Disclaimer: I did only one run with each architectures. I kept other hyperparameters the same as the previous post, but there are likely some interaction effects unaccounted for.
All code is in Python using the keras library.
Trial 1 Link to heading
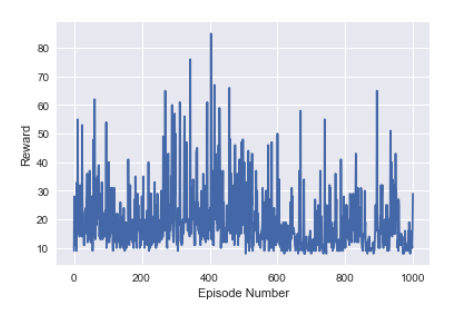
A somewhat basic network. Contains one hidden layer of medium size.
model = Sequential()
model.add(Dense(64, input_dim = input_dim , activation = 'relu'))
model.add(Dense(32, activation = 'relu'))
model.add(Dense(n_actions, activation = 'linear'))
Results were okay, reasonable. Not amazing. The agent hits max performance, but there is a lot of variance in the results.
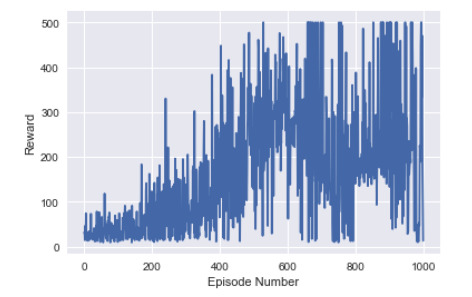
Trial 2 Link to heading
A complex network. Two hidden layers. Each layer has 128 neurons.
model = Sequential()
model.add(Dense(128, input_dim = input_dim , activation = 'relu'))
model.add(Dense(128, activation = 'relu'))
model.add(Dense(128, activation = 'relu'))
model.add(Dense(n_actions, activation = 'linear'))
Results: not good. Agent shows no sign of learning after 1000 episodes. It probably would have learned something given more time.
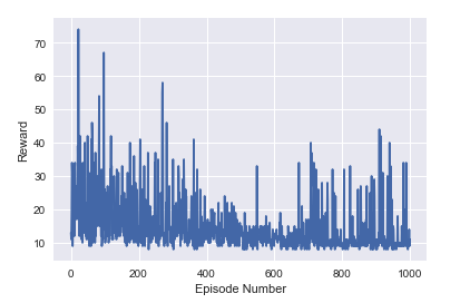
Trial 3 Link to heading
A network like that in Trial 2, but with one hidden layer instead of two. Each layer still had quite a lot of neurons.
model = Sequential()
model.add(Dense(128, input_dim = input_dim , activation = 'relu'))
model.add(Dense(128, activation = 'relu'))
model.add(Dense(n_actions, activation = 'linear'))
Results: promising. A lot less variance than in Trial 1. Better performance than Trial 2. Takes a lot longer to get anywhere, but has less variance.
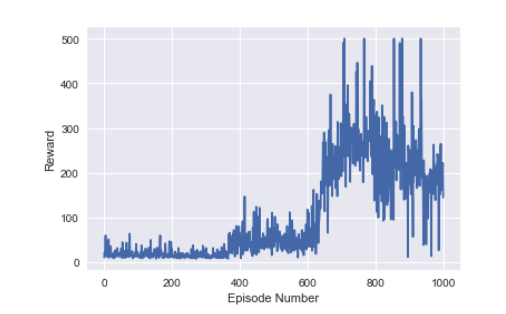
Trial 4 Link to heading
A much smaller neural network. One hidden layer. Each layer has 16 neurons.
model = Sequential()
model.add(Dense(16, input_dim = input_dim , activation = 'relu'))
model.add(Dense(16, activation = 'relu'))
model.add(Dense(n_actions, activation = 'linear'))
Results: The best of the lot. The only network that could stay at the max reward for an extended period of time. Still showed signs of catastrophic forgetting.
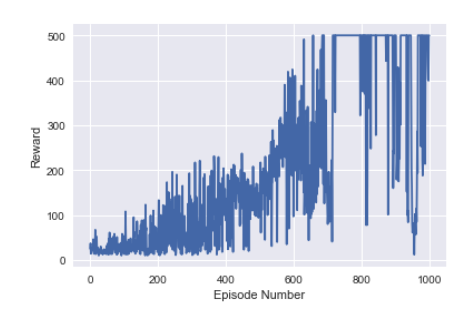
Trial 5 Link to heading
A really small neural network. Only four neurons in the first two layers.
model = Sequential()
model.add(Dense(4, input_dim = input_dim , activation = 'relu'))
model.add(Dense(4, activation = 'relu'))
model.add(Dense(n_actions, activation = 'linear'[)!]
Results: bad. Evidently the model is not complex enough to capture the environment subtleties.
Turns out complex != better Link to heading
Be careful of making your networks too complicated.
Think about the problem you are solving. Is the more complex network necessary? Selecting the wrong neural network architecture will torpedo your reinforcement learning agent.