On invariance adversarial attacks
Sensitivity-based adversarial attacks Link to heading
Neural networks are vulnerable to adversarial attack, and there’s a lot of talk about this. There are many definitions of an adversarial attack, but let’s go with this one: an input to a model designed to produce an incorrect output. Models can run on many different types of data (text, audio, tabular) but let’s use images as a working example.
The most well-known kind of adversarial attack is to add some kind of perturbation to an image to make a classifier mislabel it. The canonical example is the Fast Gradient Sign Method (FSGM) making a classifier mislabel a panda as a gibbon.
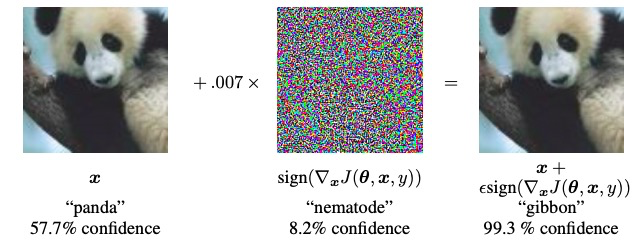
The FGSM attack at work.
In the feature space, you are taking a point, and pushing it over a decision boundary (usually the closest one) with some kind of method. This type of attack is known as a sensitivity-based adversarial attack, and they are by far the most widely-studied type of adversarial attack, with many different attacks and defences proposed.
Sensitivity-based adversarial attacks usually try to make sure a human can’t tell an image has been altered. The size of perturbations are bounded to some maximum amount $\epsilon$ so that they are unnoticeable, using some kind of $l_p$ norm to do so1.
Robust models and human perception Link to heading
To summarise the above: sensitivity-based adversarial attacks take a point $x$, and look for a decision boundary to push the point over, while also staying within some distance $\epsilon$ of $x$, as measured by some $l_p$ norm.
Regular machine-learning models cannot protect against this attack. So a new class of models is being developed. These effectively map out a $l_p$ sphere of radius $ \epsilon$ around every point, and construct the decision boundary so that it flows around these spheres. The idea is that no matter how an adversary manipulates a point, as long as they change it by no more than $\epsilon$ they will stay inside the sphere and the point won’t be misclassified. If they perturb an image by more than $\epsilon$, the attack will be more noticeable, and makes it more likely to be picked up either by a human or by some kind of attack-detection system.
But there are problems with this. Sometimes changing a point can also change its true classification, as judged by a human. Two different bounded $l_p$ perturbations on the same image can look very different to humans. One can look imperceptible, and the other can look like a totally different image.
Take this example on Imagenet that shows two examples of this effect.

Tramer et al., 2020
On the left are the original images from Imagenet, each with some classification. The centre images changes the object to something else (as measured by a human), like a goldfinch changing to a pineapple. This is an $l_2$ perturbation of some distance. On the right is a random $l_2$ perturbation of the same distance: to us, it looks the same as left image. This highlights how two $l_p$ perturbations of the same norm can have very different impacts on human perception.
Invariance-based adversarial attacks Link to heading
When you perturb a point, sometimes you might also change the ground truth label as well, like how the goldfinch changed to a pineapple in the image above. This leads to the a new category of attacks, specially designed for robust classifier: invariance attacks.
Take a picture of a 3 from a MNIST dataset. By changing 20 pixels, you can make it look like a 5 to a human. A vanilla CNN would likely categorise this as a 5, whereas a model robust to sensitivity attacks would likely still categorise this as a 3.
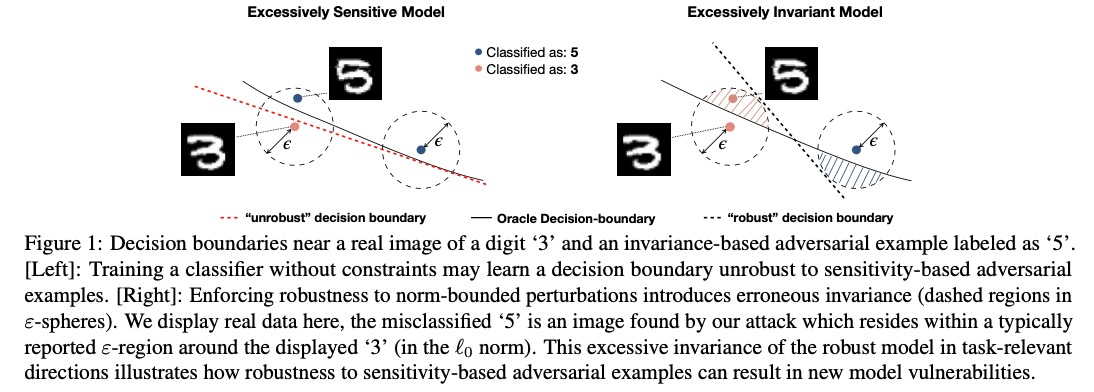 Tramer et al, 2020
Tramer et al, 2020
This is an example an invariance attack. These attacks change the original image so that its ground-truth category changes, but classifiers still think it’s the original category.
Invariance attacks work because models robust against sensitivity-based attacks try to assign the same category to everything in a $l_p$ ball around a point. The problem is that sometimes the ground-truth label of a point changes when it is perturbed, but these models still try and categorise them as the original class.
Some sensitivity-robust defences guarantee some measure of performance. Zhang et al (2019) develop a defence that guarantees test-set accuracy of 87% under $l_\infty$ perturbations of 0.4 or less. But this does not stand up against invariance examples: the guarantee applies only to old test-set labels, not new. The test-set accuracy may be over 87% under the old labelling, but invariance attacks change many ground-truth labels, so the true accuracy is much worse.
There seems to be an innate tradeoff between invariance and sensitivity. Vanilla models can be attacked with sensitivity based attacks: sensitivity-robust models are vulnerable to invariance attacks. It’s a tradeoff between the two, and for the moment we don’t have a solution.
Generating invariance adversarial examples Link to heading
What determines a ground-truth label? How do we know that a 5 is actually a 5? Usually, it has to be human labelled.
More generally, we assume the existence of an oracle that knows the absolute true label for every sample. Getting humans to label things is expensive, and so access to the oracle is also considered expensive.
Let’s keep using MNIST as an example. We would like to create invariance adversarial examples for MNIST. To recap: an invariance adversarial sample is when you take an image classified as some number (3), and create an image a human would classify as a different number (5), while changing the image no more than some limit.
How do you generate these samples? There are two ways: manually (by hand), or with an algorithm. The manual way is more effective (you can verify the output as you go), but the algorithmic way can be scaled.
I’ll report the methods of Tramer et al., 2020, who used both approaches. For the manual approach they actually created an image editor that let them change images at a pixel level, bounded by a $l_p$ constraint. Then they got humans to verify the category of the new image, and they thus confirmed that the true label for the image had been changed.
The algorithmic approach Link to heading

In dot points:
-
select a norm (e.g. $l_\infty $) and a max allowed amount of perturbation (e.g. $\epsilon = 0.3$)
-
input: an image $x$ (e.g. 3)
-
output: an invariance adversarial image $x^*$, where $x^* = x + \Delta$ ($\Delta$ is a perturbation under a $l_p$ norm, bounded by $\epsilon$), chosen such that $O(x^*) \neq O(x)$, where $O$ is an oracle who knows the “ground-truth” labels (usually a human).
-
Create two sets:
- $\mathcal{S}$ is the set of images that have a different class to $x$
- $\mathcal{T}$ is a set of small transformations. Some examples: rotating 20 degrees or less, horizontal or vertical shifts by 6 pixels or less, resizing up to 50%, or shears up to 20%.
-
Create a set $\mathcal{X}^*$ from $\mathcal{S}$ and $\mathcal{T}$, applying transformations from $\mathcal{T}$ to every element in $\mathcal{S}$
-
Search $\mathcal{X}^*$ for the closest image to $x$ under the $l_p$ norm. This image $x^*$ has a different label to $x$ (by definition of $\mathcal{S}$ ) but will be similar in pixel-space.
-
Next come some adjustments to $x^*$ to make it look more similar to $x$. Briefly:
- spectral clustering is used to identify pixel changes that are irrelevant and to create some new candidate images
- An AC-GAN calculates the likelihood of this image occurring, per class, and the best ones are selected.
Not all invariance adversarial examples created with this method were successful. Some still looked enough like the original image to be classified as such, others were “garbage” and looked like no image at all. Below we go through some results of the process.
Results Link to heading
Here are results for how often humans change their categorisation on these invariance adversarial examples. Manual adjustment works best.

How do classifiers go on these invariance adversarial examples? In a nutshell, vanilla classifiers are good at detecting invariance examples (as you would expect) while overly-robust classifiers are terrible. Here is a table with results (Tramer et al., 2020).
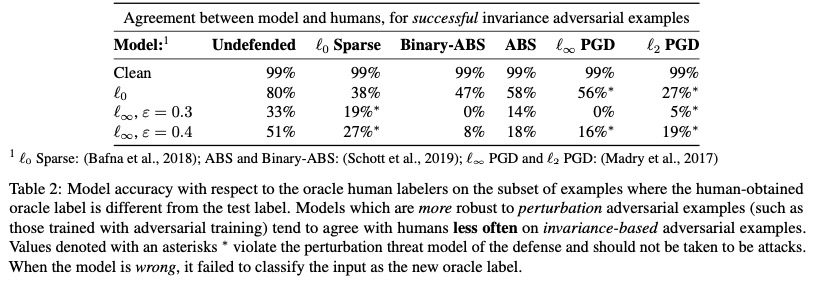 In the above ‘clean’ refers to unchanged images, and ‘undefended’ to a model not adversarially trained or made robust against sensitivity adversarial examples. All from Tramer et al., 2020.
In the above ‘clean’ refers to unchanged images, and ‘undefended’ to a model not adversarially trained or made robust against sensitivity adversarial examples. All from Tramer et al., 2020.
There’s plenty more research to be done in this area, and it’s certainly one I’m excited about.
References and further reading Link to heading
References
Florian Tramèr, Jens Behrmann, Nicholas Carlini, Nicolas Papernot and Jörn-Henrik Jacobsen. Fundamental Tradeoffs between Invariance and Sensitivity to Adversarial Perturbations (2020)
Zhang, H., Chen, H., Xiao, C., Li, B., Boning, D., and Hsieh, C.-J. Towards stable and efficient training of verifiably robust neural networks. (2019).
Further interesting reading:
Jacobsen, J.-H., Behrmann, J., Zemel, R., and Bethge, M. Excessive invariance causes adversarial vulnerability. In International Conference on Learning Representations, 2019.
Ilyas, A., Santurkar, S., Tsipras, D., Engstrom, L., Tran, B., and Madry, A. Adversarial examples are not bugs, theyarefeatures. In AdvancesinNeuralInformation Processing Systems, pp. 125–136, 2019.
Engstrom, L., Ilyas, A., Santurkar, S., Tsipras, D., Tran, B., and Madry, A. Adversarial robustness as a prior for learned representations, 2019a.
Engstrom, L., Tran, B., Tsipras, D., Schmidt, L., and Madry, A. Exploring the landscape of spatial robustness. In International Conference on Machine Learning, pp. 1802– 1811, 2019b.
-
If we use a bounded $l_0$ norm, we are placing a limit on how many pixels we can change. Bounded $l_1$ and $l_2$ norms limit the Manhattan and Euclidean distance (respectively) of perturbations in image space. A bounded $l_\infty$ norm limits the maximum distance we can change a single pixel, meaning we can change all pixels in the image up to that amount. ↩︎